订阅时事通讯
请在下方输入您的电子邮件地址并订阅我们的时事通讯
请在下方输入您的电子邮件地址并订阅我们的时事通讯

您可能已經知道如何借助穩定擴散來製作人工智慧生成的圖像。現在,您還可以透過人工智慧生成的動態圖形為這些圖片賦予新的生命。歡迎來到 穩定的 影片 擴散 它可以幫助您將靜態影像變成動態影片。在這篇文章中,我將讓您了解有關 穩定的擴散視訊生成 以及如何像專業人士一樣使用它。

如您所知,Stable Diffusion 是 Stability AI 創建的開源 AI 模型。使用穩定擴散,您只需輸入文字提示即可產生圖像。現在,透過穩定擴散的影片版本,您可以免費將影像轉換為短影片。
AI 模型將影像作為來源幀,並使用獨特的技術(稱為擴散)為其創建後續幀。該技術理想地向來源影像添加各種細節(無論是背景還是物件),使其成為影片。 Stability AI 基於大量真實影片和照片訓練了模型,該模型可以虛擬運行或在本地系統上運行。

全面的, 穩定的視訊擴散 是一個強大的工具,可以幫助您創建各種影片 - 從創意內容到教育內容。雖然該模型最近已發布,但仍在開發中,預計將來會不斷發展。
目前,您可以透過兩種方式使用 Stable Diffusion 的影片功能 – 您可以將其安裝在您的系統上或利用任何基於 Web 的應用程式。
自從 穩定擴散 AI 視頻到免費視頻 解決方案是一個開源產品,各種第三方工具已將其整合到其平台上。例如,您可以造訪以下網站: https://stable-video-diffusion.com/ 並上傳您的照片。照片上傳後,該工具將自動對其進行分析並將其轉換為影片。
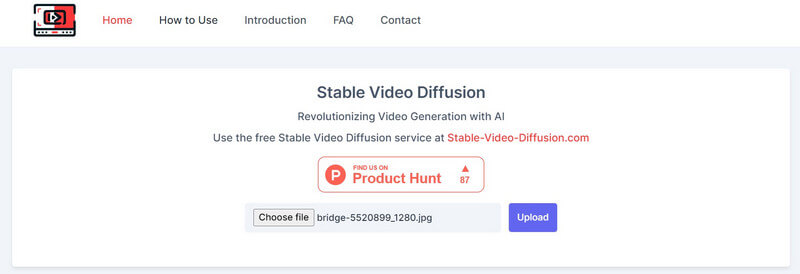
就是這樣!幾秒鐘後,線上工具就會根據上傳的照片產生一個短影片。您可以簡單地在此處預覽影片並將其下載到您的系統上。
如果您想獲得更多自訂(且未過濾)的結果,那麼您也可以考慮安裝 AI 模組 影片穩定 擴散 在您的系統上。不過,您應該知道這個過程有點技術性,並且會消耗大量的運算資源。
先決條件:
滿足上述要求後,您就可以在系統上啟動 Python 控制台。現在,您可以一一執行以下命令,這將在您的系統上建立、啟動和安裝運行穩定擴散所需的依賴項。
python3 -m venv venv
源 venv/bin/activate
pip install -r 要求.txt
一旦環境在您的系統上啟動並運行,您就可以準備輸入影像。如果您沒有圖像,您可以使用標準穩定擴散 AI 透過輸入文字來建立圖像。
要生成視頻,您只需導航 穩定視訊擴散 系統上的方向。只需輸入以下命令即可使用輸入影像產生影片:
python3腳本/dream.py –ckpt_path ckpt/stable-diffusion.ckpt –image_path input_image.png –prompt「提示文字」 –fps 6 –num_frames 100 –augmentation_level 0.5
請注意,在上面的命令中,您需要執行以下操作:
輸入提示後,稍等片刻即可 穩定的擴散視訊生成 完成其處理。如果過程更複雜,那麼穩定擴散可能需要一段時間才能產生結果。
影片生成完成後,將保存在 輸出 以時間戳記作為名稱的目錄。
这样,您就可以使用 穩定擴散 AI 視頻到免費視頻 (或免費照片到影片)產生影片的工具。您可以進一步嘗試各種提示和輸入設定來調整結果。
簡而言之,穩定擴散是 人工智慧模型 由 Stability AI 創建,用於產生高品質的媒體內容(照片和影片)。它是先前模型的更穩定版本,可產生逼真的影像而不會出現錯誤。
另一方面,不穩定擴散是其更具創造性和不受限制的對應物。與在過濾影像資料集上訓練的穩定擴散不同,不穩定擴散將未過濾的影像作為其資料集。這就是為什麼不穩定擴散經常會導致結果錯誤,並產生比現實更抽象的作品。

自從 穩定的視訊擴散 仍在不斷發展,很難預測其實際影響,但可以產生以下影響:
如您所知,Stable Diffusion 可以在幾秒鐘內生成視頻,這可以幫助內容創作者節省時間。您可以立即製作動畫、添加特效或轉移影片風格,而無需花費數小時進行編輯。
我們在影片編輯中投入的手動工作可能既昂貴又耗時。另一方面, 穩定的視訊擴散 可以透過自動化大部分後製任務來幫助您降低這些編輯成本。
創作者現在可以透過穩定擴散製作超越其有限創造力的影片。例如,它可用於產生具有逼真特效的影片或動畫靜態影像。
正如我上面所討論的,穩定擴散是一個開源工具,任何人都可以免費使用。這使其成為任何想要製作影片的人的寶貴創意資產,無論他們的技能或預算如何。

顧名思義,人工智慧模型基於傳播實踐,訓練人工智慧產生真實的媒體。它基於三個主要原則:
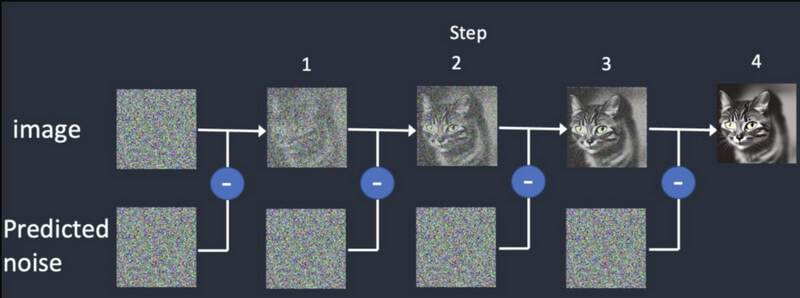
擴散:在擴散中,我們首先從隨機圖像開始,然後逐漸向其添加更多細節。它將繼續提供不同的輸出,直到與初始輸入匹配。這將訓練 穩定的擴散視訊生成 在最初的框架的基礎上提出合成框架。
訓練:就像一張圖像一樣,擴散模型是在海量資料集上訓練的。這樣,AI模型就可以輕鬆區分並產生各種真實物體。
影片生成:模型訓練完成後,使用者可以將影像載入到 AI 模型中。該模型將根據提供的顏色、旋轉、視覺偏移等輸入來細化每一幀的噪聲,並得出真實的輸出。
穩定的視訊擴散 是新發布的,有一些限制,包括以下內容:
好消息是,目前的人工智慧模型 穩定的視訊擴散 是免費提供的。 Stability AI 表示,目前該模型已出於研究目的而開發。您可以在此處的 GitHub 頁面上存取該模型的程式碼: https://github.com/Stability-AI/generative-models
除此之外,您可以在此處存取其關於 Hugging Face 的文檔: https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
Stability AI 本身進行了廣泛的研究,並將其視訊生成模型與其他工具進行了比較。根據研究,Stable Video Diffusion 與 Runway 和 Pika Labs 等模型進行了比較。

在這裡,您可以看到這些模型如何以 3-30 fps 的自訂速率產生 14 和 25 幀。在產生逼真的影片方面,Stable Diffusion 也比 Google Video Diffusion 和 DALL.E 更強大。
| 模型 | 力量 | 弱點 |
| 穩定的視訊擴散 | 真實且連貫的結果,適合靜態影像的短視頻 | 長度有限、品質參差不齊、創意控制有限 |
| 谷歌影片傳播 | 可以生成更長的視頻,適合文字到視頻的生成 | 可能會產生錯誤,需要微調(不太穩定) |
| 達爾-E 2 | 極具創意和實驗性 | 可能不太穩定 |
| 跑道ML | 易於使用,適合初學者 | 功能有限,不如其他型號強大 |
| 皮卡實驗室 | 開源 | 用戶基礎有限,仍在開發中 |
否——截至目前,調查結果 穩定的擴散視訊生成 最多只能限制 4 秒。然而,在該人工智慧即將推出的版本中,我們可能會期望它也能產生長時間影片。
以下是運行時的一些要求 穩定的視訊擴散:
| 要求 | 最低限度 | 受到推崇的 |
| 圖形處理器 | 6GB 顯示記憶體 | 10 GB VRAM(或更高) |
| 中央處理器 | 4核 | 8核(或更高) |
| 記憶體 | 16 GB | 32GB(或更高) |
| 貯存 | 10GB | 20GB(或更高) |
除此之外,您應該事先在系統上安裝Python 3.10(或更高版本)。
目前Stability AI僅發布 穩定的視訊擴散 用於研究目的,以便模型能夠發展。然而,在未來,我們可能會期望人工智慧模型具有以下特徵:
相信看完這篇文章你就能輕鬆明白 穩定的擴散視訊生成 作品。我還提出了一些您可以開始使用的快速步驟 穩定的視訊擴散 靠你自己。不過,您應該記住, 人工智慧模型 相對較新,仍在學習中,可能無法滿足您的確切要求。來吧——嘗試 Stability AI 生成視訊模型,並不斷嘗試它以釋放您的創造力!